A recent study published by Apple Research has provided significant insights into the reasoning capabilities of Large Language Models (LLMs), including GPT-4o, Llama, Mistral, and others. The findings suggest that LLMs are not capable of advanced reasoning, and their behavior is more accurately described as sophisticated pattern matching. Importantly, the research indicates that simply increasing computational power or model size is unlikely to improve the reasoning capabilities of LLMs. This implies that even future iterations, such as GPT-5, may not resolve this fundamental limitation.
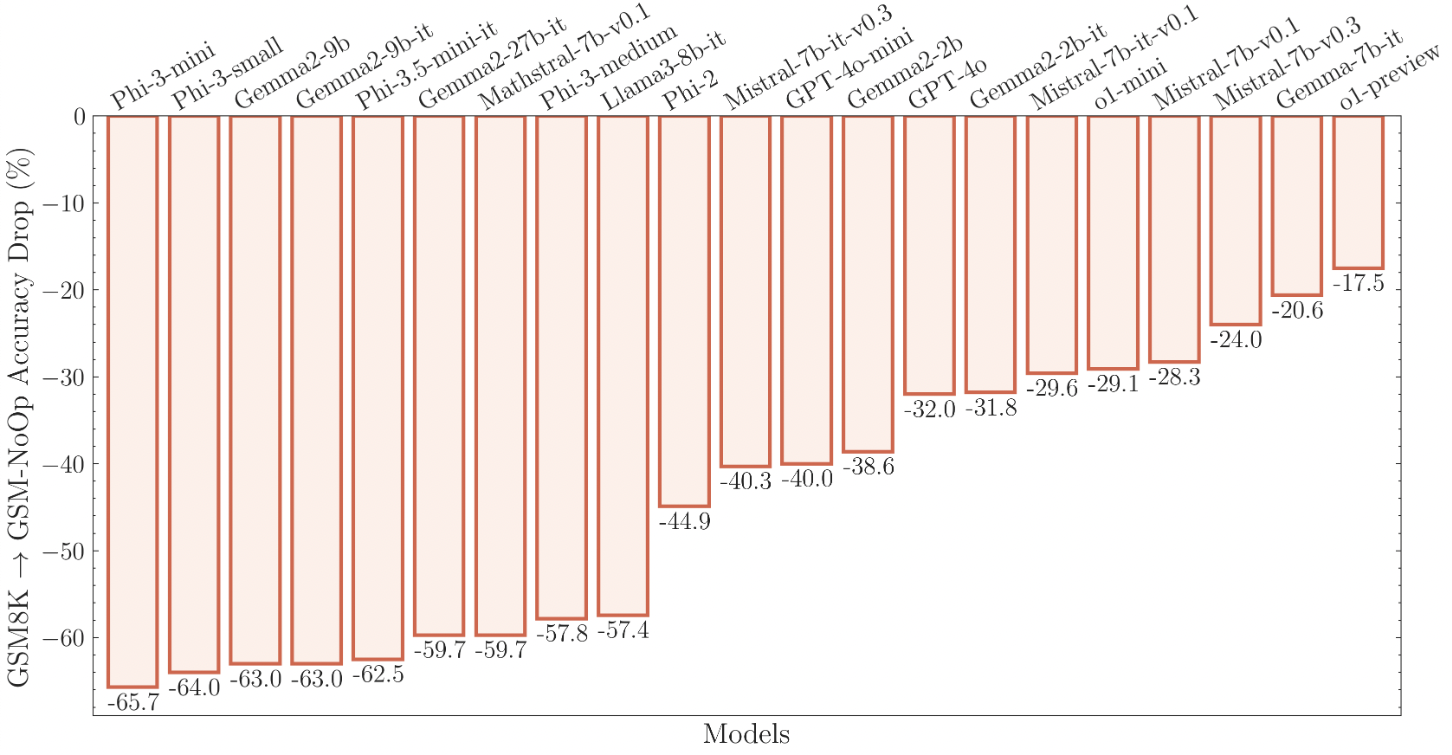
The image above illustrates the decline in performance when LLMs are presented with extraneious information to answer a question. Specifically, the study introduced one extra clause to a question. While the smallest models experienced the most significant impact on their response accuracy (over 50% decline), even OpenAI’s latest model, o1-preview, saw a 17.5% decrease. It’s worth noting that OpenAI’s o1-preview is a Chain of Thought LLM system, unlike the other systems tested. It employs multiple LLM calls behind the scenes to generate a final response, making direct comparisons with other LLM systems challenging and potentially misleading.
For organizations planning to implement LLM-based products or services, these findings underscore the importance of clearly understanding the required LLM capabilities and whether these attributes are likely to improve over time. As a general principle, features that leverage LLMs for pattern matching and structured data extraction purposes, with reasoning logic implemented in traditional programming languages, are likely to be more robust and reliable when deployed into production.



