In the rapidly evolving landscape of artificial intelligence, Large Language Models (LLMs) have emerged as a transformative force, sparking both excitement and speculation about the future of AI. While discussions often veer towards the potential of Artificial General Intelligence (AGI), it’s crucial to ground our understanding in the practical, present-day capabilities of LLMs. This blog post aims to cut through the hype and focus on the tangible strengths of LLMs from a product perspective, highlighting areas where they truly excel and can deliver immediate value.
As we explore the “good parts” of LLMs, we’ll delve into three key areas where these models are making significant impacts: natural language interfaces, structured data extraction, and cognitive programming. By examining these strengths, we can better appreciate how LLMs are reshaping product development and opening new possibilities across various industries.
Natural Language Interfaces
Natural language interfaces powered by LLMs allow users to interact with computer systems in a remarkably human-like manner, through both text and voice. These interfaces provide access to the full capabilities of an application without requiring users to understand specific programming interfaces or commands. Much like conversing with a person, the system can respond, explain its capabilities, and even suggest alternatives. For instance, it might say, “I can help you with task X, but I’m not able to do Y. However, I could assist you with Z as an alternative approach.” This intuitive interaction style makes complex systems more accessible and user-friendly, opening up new possibilities in areas such as customer support, virtual assistants, and interactive documentation.
Context Windows are Expanding
Context Windows are like the short-term memory of an AI model. They represent how much information the AI can “remember” and work with at one time.
Imagine you’re having a conversation with a friend. The context window is like how much of that conversation you can keep in your mind without forgetting earlier parts. A larger context window means the AI can handle longer, more complex conversations or tasks without losing track of important details.
For example, if you’re using an AI to summarize a long article, a model with a small context window might only be able to work with a few paragraphs at a time. This could lead to a disjointed summary. On the other hand, a model with a large context window could potentially read and understand the entire article at once, producing a more coherent and comprehensive summary.
Here’s a list of some of the notable LLM’s available today and their context window lengths:
| Model | Context Window |
|---|---|
| Gemini 1.5 Flash | 1,000,000 |
| Claude 3 Opus | 200,000 |
| Claude 3 Sonnet | 200,000 |
| Claude 3 Haiku | 200,000 |
| Claude 3.5 Sonnet | 200,000 |
| GPT-4 Turbo | 128,000 |
| Gemini 1.5 Pro | 128,000 |
| GPT4o | 128,000 |
| GPT-4o mini | 128,000 |
| GPT-4-32k | 32,000 |
| Gemini Pro | 32,000 |
| Mistral Medium | 32,000 |
| Mistral Large | 32,000 |
| GPT-3.5 Turbo | 16,000 |
| Mistral Small | 16,000 |
| GPT-4 | 8,000 |
| Llama 3 Models | 8,000 |
| GPT-3.5 Turbo Instruct | 4,000 |
| Nemotron | 4,000 |
A year ago, GPT-4 had a 128k context window so we’ve seen a 10x increase in context window size. Fundamentally, larger context windows allow natural language interfaces to immediately access more information.
Find the Needle in the Haystack
LLMs are getting significantly better at finding data in a large context windows. Testing with GPT-4 found that you can reliably retrieve data in a 64k+ token prompt. Beyond 64k tokens, the retrieval performance degrades especially when searching for information at the beginning of the prompt.

64k tokens is the size of a short novel. You could fit the majority of the days news in a 64k token window. Fancy a chat with the day’s news?
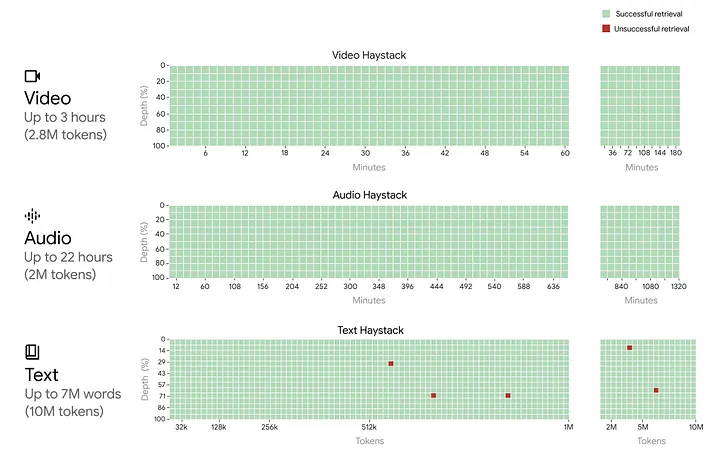
But GPT-4 isn’t state of the art in this space. Google Gemini 1.5 Pro has a 1M token context window and it can accurately recall information 99% of the time. For comparison, 1M tokens is the size of the entire Harry Potter series. You could generate the next book in the series following canon, Harry Potter and the Midlife Crisis.
Voice App Infrastructure has Arrived
There’s now a suite of tools available for building voice apps. First, there’s voice-to-text API’s to convert spoken words into text. Then there’s the LLMs that can use their memory to understand the user’s intent and generate a response. Lastly, there’s text-to-speech API’s to convert the text response back into emotive spoken words.
Voice-to-Text & Vica Versa Services
Voice Infrastructure
To build low latency voice apps, you need to use a WebRTC serving infrastructure. Until recently, most WebRTC platforms were built for live stream broadcasting and video conferencing. Voice apps need the user’s audio to reach the speech-to-text API as quick as possible then pipe it to the LLM then send it to the text-to-speech API before returning the response to the user. High quality consumer experiences require a customized WebRTC stack to make this happen quickly (low latency).
Here’s a few example of WebRTC Providers customizing their offeringsfor Voice Apps:
Structured Data Extraction
In traditional computation, it’s difficult to extract structured data from sources such as:
- Websites
- PDFs
- Images
- Videos
Expensive and brittle data pipelines have been built for decades to attempt this task. LLMs have effectively solved the task at a development speed unrivaled by prior methods.
The implications of this are profound. Previously unsearchable data sources are now searchable. An image becomes queryable like a database. An HTML website practically becomes a public API. When building a product, it’s important to consider the public and private data sources that haven’t been exploited yet by the LLM revolution.
To illustrate this concept, let’s consider a practical example that a non-technical person can understand:
Imagine you’re a small business owner who wants to keep track of your competitors’ pricing. Traditionally, you might have to manually visit each competitor’s website, find the prices for various products, and input this data into an Excel spreadsheet. This process is time-consuming and prone to errors.
Now, with LLM-powered data extraction, you could create a simple data pipeline that:
- Automatically visits your competitors’ websites
- Uses an LLM to understand the structure of each website and locate product information
- Extracts product names, prices, and other relevant details
- Organizes this information into a structured format
- Generates an Excel spreadsheet with neatly organized competitor pricing data
This LLM-powered pipeline could run daily or weekly, providing you with up-to-date competitive intelligence without manual effort. The LLM’s ability to understand and adapt to different website layouts means your pipeline remains functional even if competitors change their site design, making it more robust than traditional web scraping methods.
This example demonstrates how LLMs can transform unstructured web data into valuable, structured business intelligence, saving time and providing insights that were previously much harder to obtain.
Cognitive Programming
Dynamic programming used to be driven by pre-defined rules and data structures. LLMs are enabling a new generation of cognitive programming where the program doesn’t have pre-defined structures, the LLM generates on the fly. For example, a cognitive program can adapt its behavior based on user input without being explicitly programmed for every possible scenario.
To illustrate this concept for non-technical readers, imagine a traditional GPS navigation system versus an AI-powered assistant. A traditional GPS follows pre-programmed routes and rules, like always avoiding toll roads if that’s the setting. In contrast, a cognitive program using an LLM could understand a request like “I’m in a hurry, but I also want to enjoy some scenery” and dynamically create a route that balances speed and scenic views, even if that specific combination wasn’t pre-programmed. It can interpret the nuanced request and generate a tailored solution on the spot, much like a human would reason through the problem.
Conclusion
The rapid evolution of AI and machine learning is fundamentally changing the way we interact with technology, creating better human-computer interfaces that enhance our daily lives and work experiences. From voice-driven AI applications making our interactions more natural, to the ability to extract structured data from unstructured sources, and cognitive programming adapting to our needs, these advancements represent a significant step towards more human-centric technology.
These technologies are not just improving efficiency; they’re enhancing the quality of our interactions with technology and, by extension, improving our quality of life. By simplifying complex tasks, providing more personalized experiences, and freeing up our time and mental energy, AI and machine learning are helping us focus on more creative and fulfilling pursuits.
Ultimately, the AI revolution is about reimagining the relationship between humans and computers. It’s not just about advancing technology for its own sake, but about creating tools that are more accessible, intuitive, and in tune with our natural ways of thinking and working. As we continue to develop and refine these technologies, we’re designing new ways for technology to enhance and empower human potential.



